
Introduction#
I attended ECAI ‘25 to present a paper that got accepted titled “Safe Reinforcement Learning in Black-Box Environments via Adaptive Shielding”. In this blog post I will walk you through the paper in a more informal manner and how the method we proposed, ADVICE works. Take a look at any of the links above before you read the rest of this post.
At the highest level, ADVICE is a post-shielding method for the safe training of reinforcement learning (RL) algorithms. The key part is that unlike all prior methods in the literature, ADVICE uses no prior knowledge about the environment/task/safety constraint to protect the agent. To make this blog post an easy read, I will cover a brief introduction into safe RL, the ADVICE method, our results, and finally where future work could look towards. I encourage you to check out our GitHub implementation also!
Motivation#
RL is powerful because an agent can learn complex behaviours through trial and error, improving a policy by interacting with the environment [1]. The problem is that “trial and error” is exactly what you do not want in safety-critical settings: early exploration can involve crashes, unsafe states, or other catastrophic outcomes, long before the agent has learned anything sensible. Safe RL tries to tackle this by ensuring learning happens while keeping unsafe behaviour under control [2].
A lot of the safe RL literature manages safety by adding extra structure: explicit cost signals [3] (so the agent is penalised whenever it does something dangerous), formal constraints [4] (so unsafe behaviours are ruled out by specification), or learned safety models built from prior data [5]. These ideas can work well, but they typically assume you already know what “unsafe” means in a way you can encode, or that you can at least measure it continuously during training.
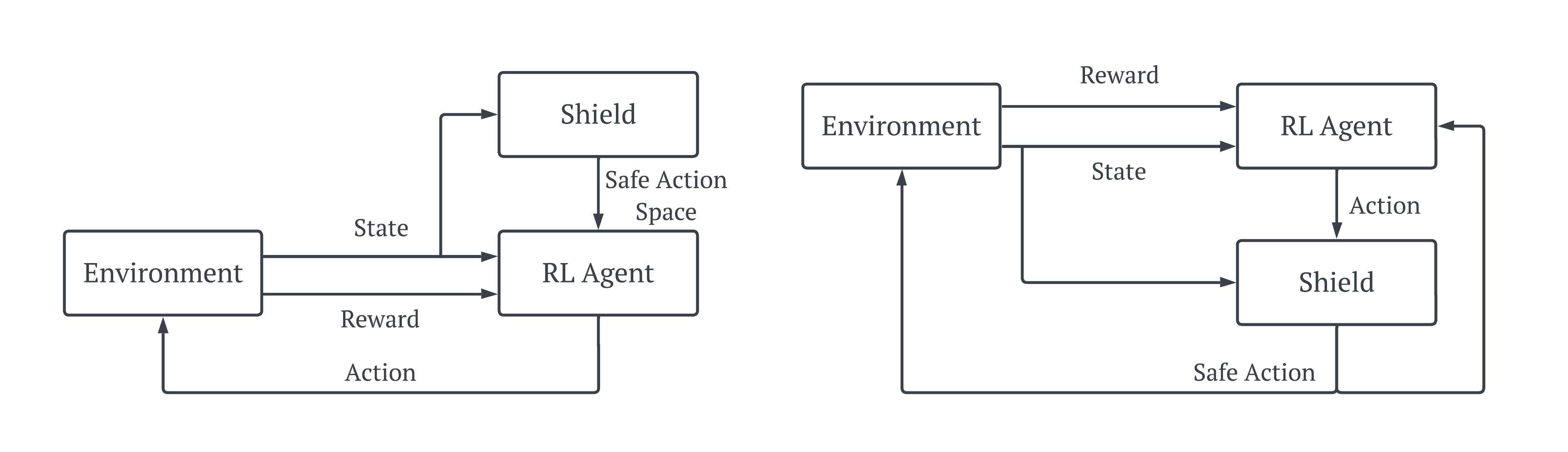
Shielding is one of the cleanest ways to think about safety in this space: a shield sits between the agent and the environment, either restricting the action set before action selection (pre-shielding) or checking and correcting actions after they’re chosen (post-shielding). A diagram can be seen above. The issue is that most shields still rely on prior knowledge (rules, constraints, or environment models) to decide what is safe.
That is where black-box environments make things awkward. In a genuinely black-box setting, you have no task-specific safety rules, no model of the dynamics, and often no explicit cost signal, just whatever the agent experiences online. This is the motivation for ADVICE: we want a post-shield that can be synthesised end-to-end from experience in continuous state/action spaces, learning what separates safe from unsafe behaviour without hand-crafted constraints or prior domain knowledge.
ADVICE#
ADVICE is designed as a post-shield for black-box RL, so it does not assume you have a model of the environment, a handcrafted constraint, or a dense cost signal. Instead, it builds its own notion of “safety” directly from the agent’s experience, and then uses that knowledge to filter future actions. The method has two stages: a construction phase where it learns a safety representation, and an execution phase where it actively shields the agent and adapts how cautious it is. See the high-level overview in the Figure below.
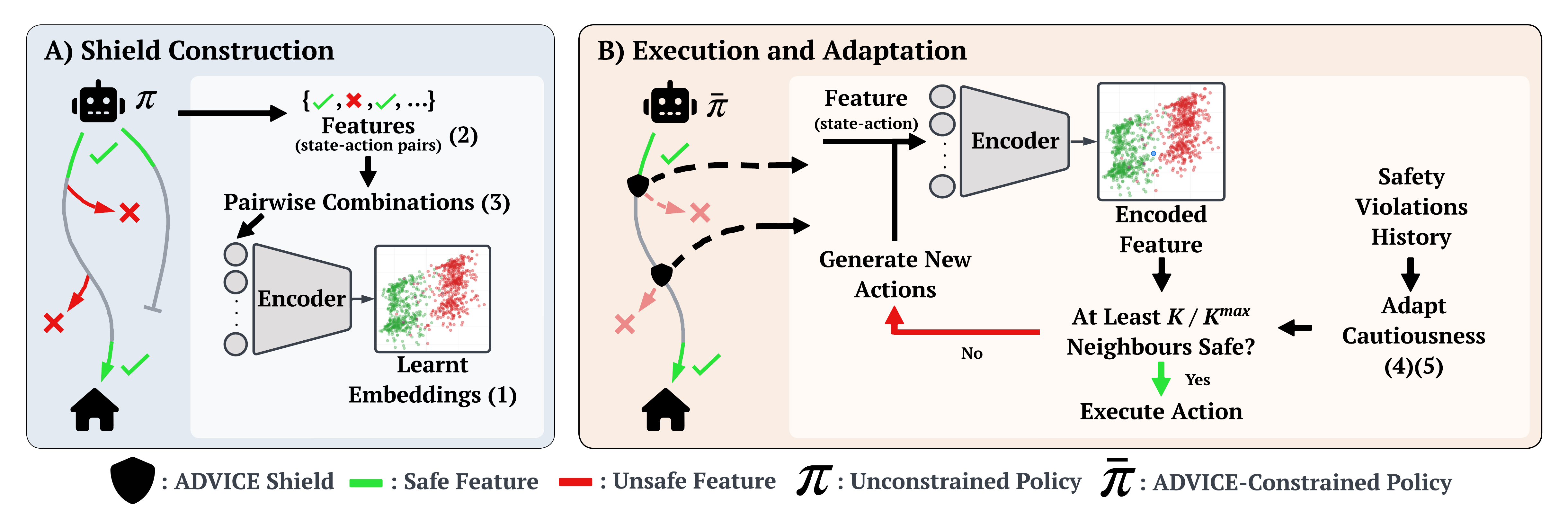
Shield Construction#
During shield construction, the agent first interacts with the environment unshielded for an initial period of \(E_{max}\) episodes. ADVICE records features of the form \(f_t = (s_t, a_t)\), i.e., the observed state and the action chosen at time \(t\). These features are labelled using only standard MDP termination information: a feature is treated as safe if it is associated with an accepting outcome or the initial feature \( f_{t_0}\ \), and unsafe if it leads to a non-accepting terminal outcome (a safety violation); everything else is treated as inconclusive. This is done simply by the python code below.
if self.env.task.goal_achieved or (step == 0):
self.safe_observations.append((prev_state, action))
if cost > 0:
self.unsafe_observations.append((prev_state, action))From the collected safe and unsafe sets, ADVICE forms pairwise combinations and assigns them contrastive labels: safe + safe and unsafe + unsafe pairs are similar, while safe + unsafe pairs are dissimilar. A contrastive autoencoder, using the contrastive loss:
def contrastive_loss(y_true, y_pred, margin=1.0):
square_pred = tf.square(y_pred)
margin_square = tf.square(tf.maximum(margin - y_pred, 0))
return tf.reduce_mean(y_true * square_pred + (1 - y_true) * margin_square)is then trained on these pairs, combining a reconstruction objective with the above contrastive objective so that the latent space both preserves the structure of \((s,a)\) and separates safe from unsafe behaviours. After training, ADVICE fits a simple nearest-neighbours model in the learned latent space, enabling fast safety queries for new \((s,a)\) pairs.
Execution and Adaptation#
During shield execution and adaptation, ADVICE is inserted into the standard RL loop as a post-shield. At each timestep, the policy proposes an action \(a_t\) in state \(s_t\), forming \(f_t = (s_t, a_t)\). ADVICE encodes \(f_t\) into the latent space and retrieves the \(K_{\max}\) nearest neighbours; it then counts how many of these neighbours are labelled safe. If at least \(K\) neighbours are safe, the action is deemed safe and executed. Otherwise, ADVICE intervenes by generating a set of candidate alternative actions via simple quantisation of each action dimension, filtering these candidates through the same latent-space safety test, and selecting a safe replacement action that is also high-value under the agent’s current critic estimate \(Q(s_t,a)\). If no candidate action is predicted safe, ADVICE defaults to executing the original action, since no safer alternative can be identified reliably. The shielding code can be seen below.
def shield(self, current_state, original_action, step_size=1.0):
# Process safety check in batches and only keep safe actions
def is_safe_action_batch(states, actions):
safe_actions = []
embeddings = get_embeddings(states, actions)
nearest_neighbours_indices = self.neighbours.kneighbors(embeddings, return_distance=False)
predicted_classes = self.y[nearest_neighbours_indices]
safe_counts = np.sum(predicted_classes == 'safe', axis=1)
safe_indices = np.where(safe_counts >= self.neighbours_count)[0]
safe_actions = actions[safe_indices]
return safe_actions
# Check if the original action is safe
original_embedding = get_embeddings(np.array([current_state]), np.array([original_action]))
nearest_neighbours_indices = self.neighbours.kneighbors(original_embedding, return_distance=False)
predicted_classes = self.y[nearest_neighbours_indices].flatten()
safe_count = np.sum(predicted_classes == 'safe')
if safe_count >= self.neighbours_count:
return original_action
# Convert generator to array for batch processing
possible_actions = np.array(list(generate_possible_actions(step_size)))
repeated_states = np.repeat(current_state[np.newaxis, :], len(possible_actions), axis=0)
safe_actions = is_safe_action_batch(repeated_states, possible_actions)
if len(safe_actions) > 0:
critic_values = self.critic.predict([np.tile(current_state, (len(safe_actions), 1)), safe_actions], verbose=0)
max_index = np.argmax(critic_values)
return safe_actions[max_index]
else:
# If no safe actions were found, return the fallback action
return original_actionAdding the shield into the standard RL loop is simple. The shield will return the original action, proposed by the policy, if it was deemed safe; and it will replace it with an alternate action if not.
action = self.policy(tf.expand_dims(tf.convert_to_tensor(prev_state), 0))
if trained:
action = self.shield(prev_state, action)
new_state, reward, cost, terminated, truncated, info = self.env.step(action)Finally, ADVICE adapts its cautiousness by updating \(K\) online based on recent safety outcomes. It tracks the rate of terminal safety violations using a short recent window and a longer distant window. If the recent violation rate rises above the longer-term baseline (by roughly one standard deviation), ADVICE increases \(K\) to become more conservative; if the agent has been consistently safe, ADVICE decreases \(K\) (but not below approximately \(K_{\max}/2\) as this would lead to actions that are considered more unsafe than safe) to allow more exploration. This simple feedback mechanism helps ADVICE balance safety and learning progress.
Results#
I don’t want show you too many results as that could get pretty overwhelming, so instead I will summarise the most important results and you can find the rest in the paper.
In the semi-random goal environment from the Safety Gymnasium benchmark (figure below), ADVICE maintains competitive average reward while substantially reducing cumulative safety violations compared to all baselines. Importantly, most of the alternative safe RL methods shown (e.g., DDPG-Lag, RCPO, CSC) rely on an explicit cost function during training, whereas ADVICE does not. Despite operating without a cost signal, ADVICE achieves fewer violations than these cost-based approaches. At the same time, cumulative goal reaches remain comparable, showing that the safety gains do not meaningfully harm task performance. The clear separation between safe and unsafe features in the latent space supports why ADVICE can intervene effectively without predefined constraints.

The example trajectories in the figure below qualitatively show how ADVICE manages to reduces violations. The standard agent (left) tends to take more direct but riskier paths through obstacle-dense regions, leading to more collisions over time. In contrast, the ADVICE agent (right) adopts a slightly more cautious route, steering around high-risk areas while still progressing toward the goal.

If ADVICE qualitatively follows safer but longer trajectories around obstacles, then hypothetically, giving it more time should allow it to recover the reward gap. To test whether ADVICE’s slightly lower reward was simply a consequence of taking more cautious, longer routes, we increased the maximum episode length and plotted the results below. When the horizon is extended (\(T=2000\)), cumulative goal reaches increase and average reward becomes much closer to the other methods, while safety violations remain substantially lower. This suggests the earlier reward difference is primarily a time-budget effect, not a failure to learn the task effectively.

Finally, the results below show that ADVICE can be pretrained once (here, on the random goal environment) and then transferred to a related but different setting (the semi-random goal), which introduces a mild distribution shift. After transfer, ADVICE still keeps safety violations dramatically lower than the other methods, while maintaining broadly comparable reward and goal-reaching trends.

In contrast, pretraining helps Tabular Shield and CSC much less: Tabular Shield remains brittle under high-dimensional variation, and CSC still struggles when safety-relevant feedback is sparse. Overall, this suggests ADVICE’s learned latent notion of “unsafe behaviour” generalises across similar environments, making it a practical option when you want a safety mechanism that survives moderate changes in the task distribution.
Conclusion#
In this paper, we introduced ADVICE, a post-shielding approach that enables safe reinforcement learning in continuous, black-box environments without requiring prior knowledge or explicit cost signals. By learning a contrastive representation that separates safe and unsafe state–action pairs, ADVICE significantly reduces safety violations while maintaining competitive task performance—even outperforming several cost-based methods. Future work will explore faster shield activation, more efficient action selection mechanisms, and integrating uncertainty-aware components to further improve robustness under distributional shift. I encourage you to read the full paper, published at ECAI ‘25, and check out the codebase in the GitHub repo below.
References#
[1] Sutton, R.S. and Barto, A.G., 1998. Reinforcement learning: An introduction (Vol. 1, No. 1, pp. 9-11). Cambridge: MIT press.
[2] Garcıa, J. and Fernández, F., 2015. A comprehensive survey on safe reinforcement learning. Journal of Machine Learning Research, 16(1), pp.1437-1480.
[3] Altman, E., 1998. Constrained Markov decision processes with total cost criteria: Lagrangian approach and dual linear program. Mathematical methods of operations research, 48(3), pp.387-417.
[4] Könighofer, B., Rudolf, J., Palmisano, A., Tappler, M. and Bloem, R., 2023. Online shielding for reinforcement learning. Innovations in Systems and Software Engineering, 19(4), pp.379-394.
[5] Srinivasan, K., Eysenbach, B., Ha, S., Tan, J. and Finn, C., 2020. Learning to be safe: Deep rl with a safety critic. arXiv preprint arXiv:2010.14603.
Codebase#
All the material needed to use ADVICE for the safe exploration of reinforcement learning agents.