
Introduction#
I attended SAC ‘26 to present a paper that got accepted titled “Learning to Navigate Under Imperfect Perception: Conformalised Segmentation for Safe Reinforcement Learning”. In this blog post I will walk you through the paper in a more informal manner and explain how the method we proposed, COPPOL, works. I recommend taking a look at the paper first before continuing with the rest of this post.
At the highest level, COPPOL combines conformal prediction with reinforcement learning to enable safer robot navigation when perception is imperfect. To keep this blog post easy to follow, I will first introduce the motivation and background, then explain how COPPOL works, followed by the experimental results, and finally discuss possible future directions.
Motivation#
Off-world robots rarely navigate using only what they see directly in front of them. In practice, navigation is often hierarchical: orbital assets provide a broad, high-level view of the terrain, while the robot itself handles local motion and hazard avoidance on the ground. A good example is NASA’s Perseverance rover. Its team plans the basic route using images taken from orbit by missions such as the Mars Reconnaissance Orbiter (MRO), and Perseverance then uses its onboard navigation and hazard cameras to make local driving decisions during execution [1].

That overall pipeline is powerful, but it depends on perception being good enough. In off-world environments, that assumption is fragile. Vision systems can be affected by dust, poor visibility, shadows, occlusions, and sensor degradation or noise. NASA materials note that dust can obscure images and interfere with camera performance, while radiation can corrupt measured pixel signals, introduce detector noise, and damage sensitive components [2].
This creates a real safety problem. A rover may have a sensible global route and a safety-aware local planner, but if a crater, rock field, or water hazard is missed by perception, then that hazard may never appear in the map the planner relies on. At that point, the planner is not really making an unsafe choice; it is making a choice based on an incomplete view of the world. And that leads to the key insight behind our work: you cannot be safe from a hazard you do not perceive.
This is exactly the gap COPPOL is designed to address. Rather than trusting a segmentation model’s hazard predictions at face value, we ask: how can we account for the possibility that some hazards were missed?
COPPOL#
COPPOL is a conformal-driven perception-to-policy learning approach (See the overview figure below) that converts raw imagery into calibrated hazard maps for downstream navigation. COPPOL comprises (A): real-world imagery captured via satellites of a rover’s local terrain, (B): a convolutional U-Net that segments hazardous terrain at the pixel level with uncertainty calibration through conformal prediction, and (C): an RL agent that plans safe trajectories across the risky terrain.
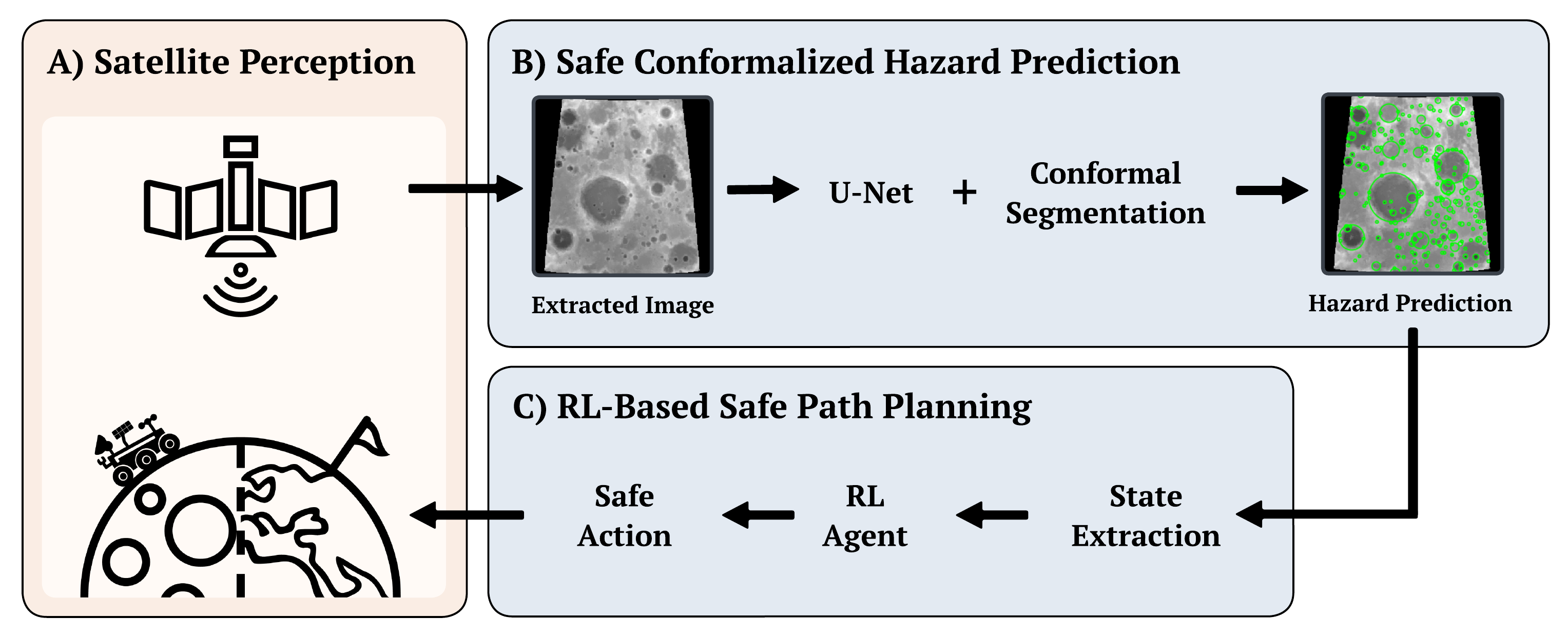
Unlike traditional pipelines where the RL agent consumes raw or thresholded segmentation outputs, COPPOL treats calibrated hazard regions as integral information, allowing the policy to reason over safety-aware spatial representations rather than uncalibrated predictions. This decoupling of perception and planning under explicit risk guarantees enables principled navigation in environments where perception errors can have harmful consequences.
Safe Conformalized Hazard Prediction#
A standard segmentation model outputs a single mask, but that mask can miss parts of the true region even when it appears confident. Conformal segmentation adds a calibration step on top of the model so that, instead of blindly trusting the raw prediction, we adjust it using evidence from a held-out calibration set \( \mathcal{D} _{\text{cal}} = {(x_i, y_i)} _{i=1}^n \). This lets us choose a risk level \( \alpha \in (0,1) \) and construct a conformalized mask that is more likely to cover the true region with a finite-sample guarantee.
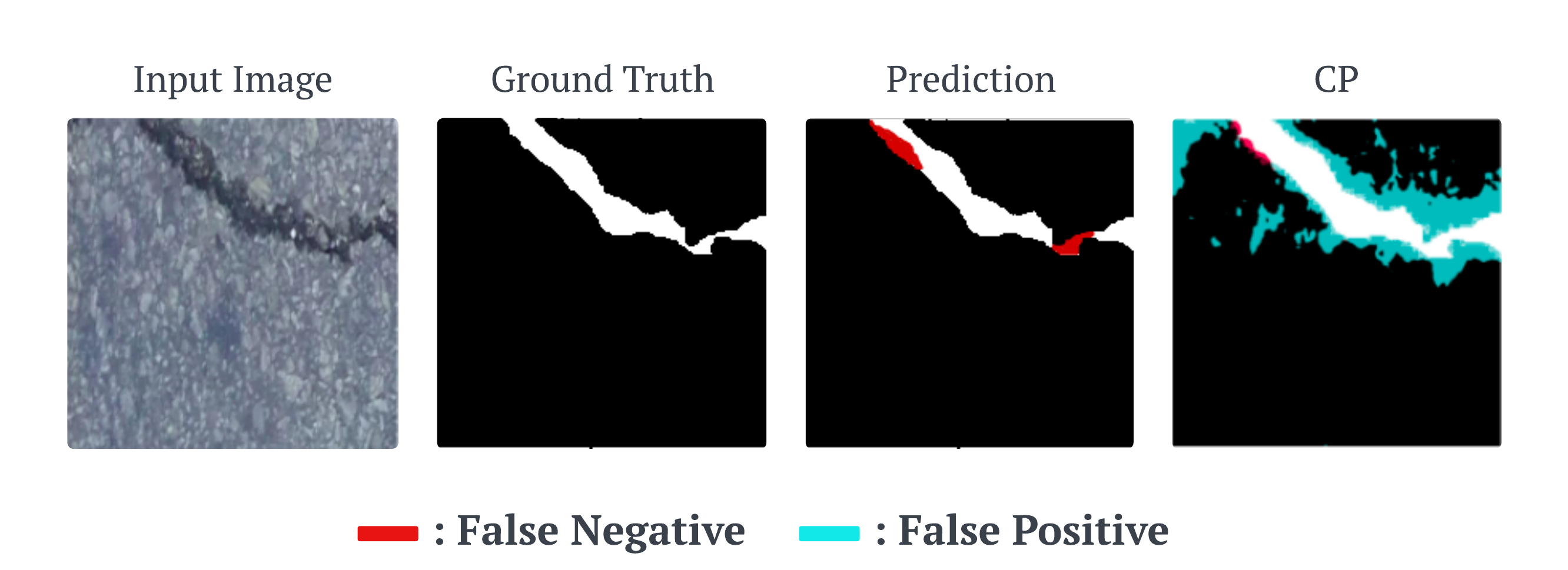
In practice, this often means making the prediction a little more conservative. The conformalized mask may include some extra pixels (as seen in the overview figure above), but it is less likely to miss important parts of the object or hazard. In the figure above, the raw prediction misses hazardous pixels, while the conformalized output expands the region to recover much of that missed area. For safety-critical tasks, that is often the right trade-off: a few extra cautious pixels are far preferable to overlooking a genuine hazard.
COPPOL starts with the first stage, Safe Conformalized Hazard Prediction, where the goal is to turn a raw terrain image into a hazard map that is not only useful, but also calibrated for safety. We begin with a standard U-Net, which takes an input image and outputs a per-pixel hazard probability map. In a normal segmentation pipeline, the next step is simple: choose a threshold \( \lambda \), mark pixels above that threshold as hazardous, and use the resulting binary mask as the final prediction. The problem is that this threshold is usually picked in an ad hoc way, for example by validation tuning, and once fixed it simply commits the system to one point on the precision–recall trade-off. That may be fine for ordinary segmentation, but it gives no formal guarantee about the thing we care most about here: missed hazards.
COPPOL replaces that hand-picked threshold with a conformal one. Instead of committing to a single threshold from the start, we consider a whole family of candidate hazard masks, ranging from less conservative to more conservative ones. As the threshold becomes more permissive, the predicted hazardous region expands and covers more of the terrain. This is important, because for safe navigation it is often better to slightly overestimate a hazard than to miss it completely. In other words, we would rather give the rover a cautious map than a sharp-looking map that silently leaves out dangerous terrain.
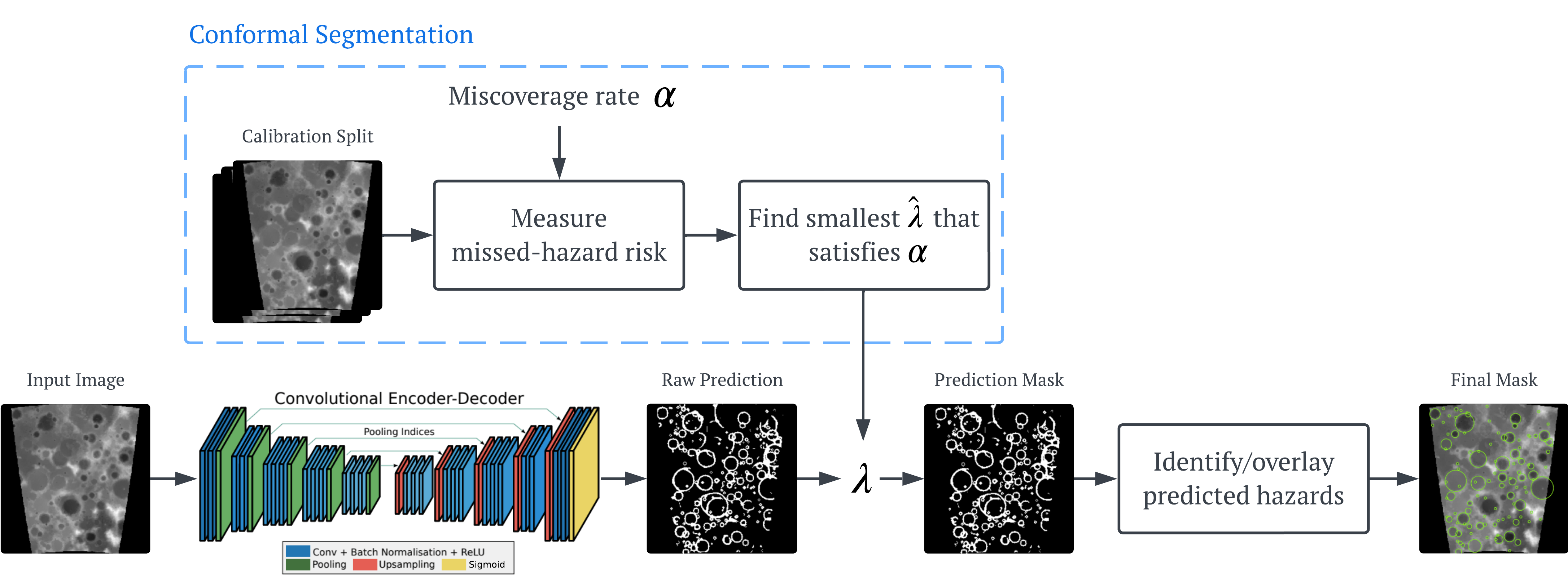
To decide which threshold to use, we calibrate on a held-out calibration split. For each candidate \( \lambda \), we measure how much true hazardous terrain is missed by the corresponding mask, using the pixel-level false negative rate (FNR) as the risk score. Intuitively, this tells us what fraction of real hazard pixels the prediction failed to capture. We then search for the smallest threshold \( \hat{\lambda} \) that satisfies a user-chosen miscoverage level \( \alpha \). Once found, that conformal threshold is fixed and used at test time to convert new U-Net probability maps into calibrated binary hazard masks. Under the standard exchangeability assumption, this gives a finite-sample guarantee that the expected missed-hazard rate on unseen data is bounded by \( \alpha \). This full pipeline of this stage can be seen in the figure above.
The end result is a hazard map that is deliberately safety-aware. It may be a little larger than the raw segmentation output, and it may include some extra cautious pixels, but that is exactly the point. In COPPOL, we are not trying to produce the prettiest segmentation mask; we are trying to produce one that is reliable enough to support downstream planning. These calibrated masks are then passed to the next stage of the pipeline, where the RL agent uses them as a risk-aware view of the world when planning its route.
RL-Based Safe Path Planning#
Once COPPOL has produced a calibrated hazard map, the second stage is RL-based safe path planning (a pipeline of this stage is shown in the figure below). This calibrated map becomes the environment seen by the agent, so the rover no longer plans from raw terrain imagery or uncalibrated predictions, but from a more safety-aware view of the world.
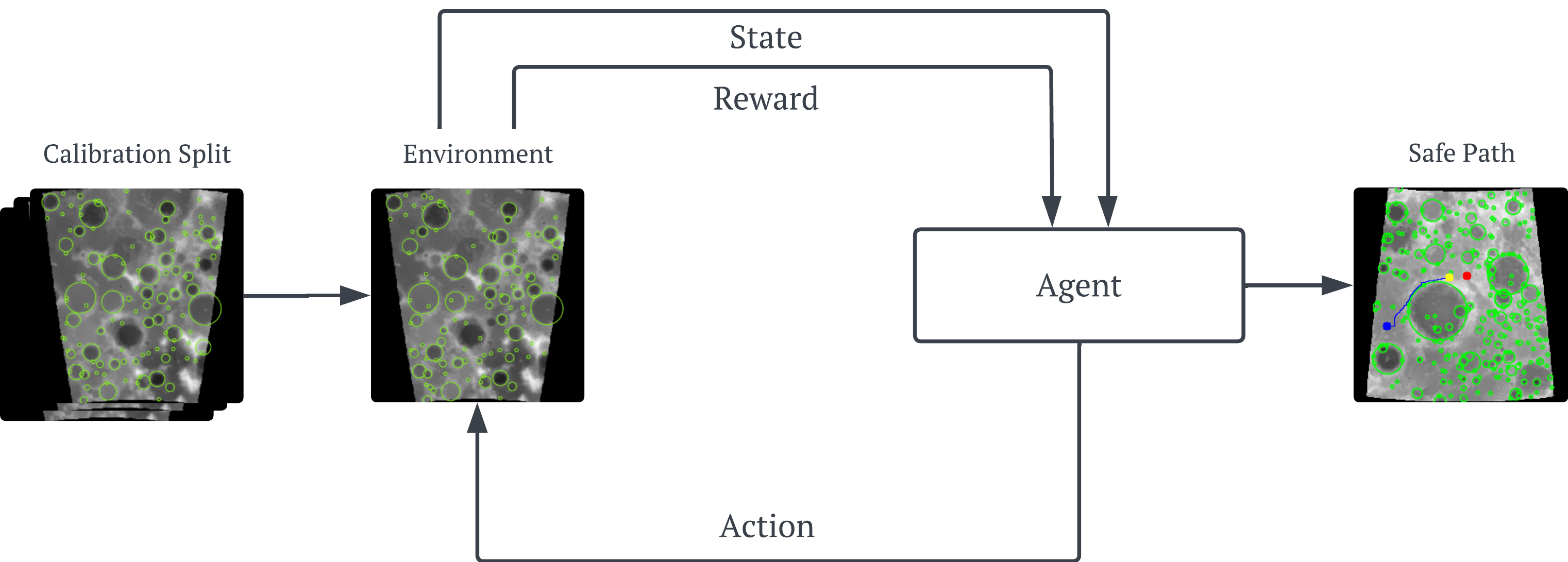
The agent then learns a navigation policy by interacting with this environment step by step. In COPPOL, the reward is designed to capture the core navigation trade-off: the agent is rewarded for making progress towards the goal, receives a small step cost to encourage shorter paths, gets a large bonus for reaching the goal, and is penalised whenever it enters or remains inside a predicted hazardous region. This encourages the rover not just to arrive, but to arrive safely.
We use RL here because the rover is planning under a hazard map that may still be imperfect, noisy, or partially incomplete, even after calibration. In that setting, navigation is not just about finding a shortest path on a fixed clean map; it is about learning how to act safely when the perceived world may not be fully reliable. COPPOL’s conformal stage reduces missed hazards and turns the image into a risk-calibrated cost field, and RL is then used to learn a policy that can repeatedly trade off progress, efficiency, and caution over an entire trajectory under that uncertain representation. Rather than assuming the map is exact, the agent learns behaviour that is shaped by the noisy, safety-aware map it is actually given, which is exactly what we want for real deployment under imperfect perception.
Because the planner operates on a conformalized, risk-aware map rather than raw predictions, it is deliberately more cautious about missed hazards. This leads to paths with greater clearance from dangerous regions and less time spent in unsafe areas, while still maintaining strong navigation performance.
Results#
I don’t want show you too many results as that could get pretty overwhelming, so instead I will summarise the most important results and you can find the rest in the paper.
We evaluate COPPOL on two datasets, YTU-WaterNet and DeepMoon, using four navigation agents: two baseline agents and two COPPOL-based agents. The Baseline agent uses the standard perception-to-planning pipeline, while MC adds Monte Carlo uncertainty estimation to show that the gains we observe are not simply due to adding generic uncertainty quantification, but specifically from the finite-sample guarantees provided by conformal prediction. We also compare against CRC, a strong state-of-the-art conformal baseline, and MC-CP, a more modern conformal variant that incorporates additional uncertainty estimation to achieve more robust coverage. These two COPPOL agents also show that the conformal prediction algorithm used in COPPOL can be any relevant method not just one specific one, improving its generalisability/applicability.
If you want to learn more about how MC-CP works, check out my separate paper explained post below, where I walk through the method from another of my papers published at AAAI ’24.
Qualitatively, in the figure below, the COPPOL variants produce noticeably more conservative and complete hazard maps than the baseline and MC agents on both datasets. On DeepMoon, CRC and especially MC-CP recover more crater regions and better cover crater boundaries, whereas Baseline and MC miss more hazards. On YTU-WaterNet, the same pattern holds: the conformal agents produce more continuous safety margin around the water boundary, which is exactly what we want for downstream safe navigation.
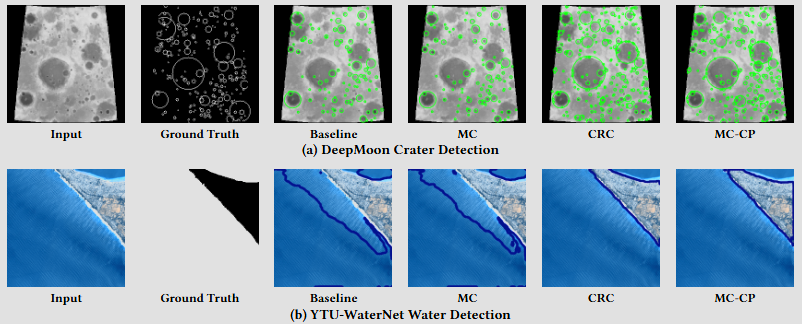
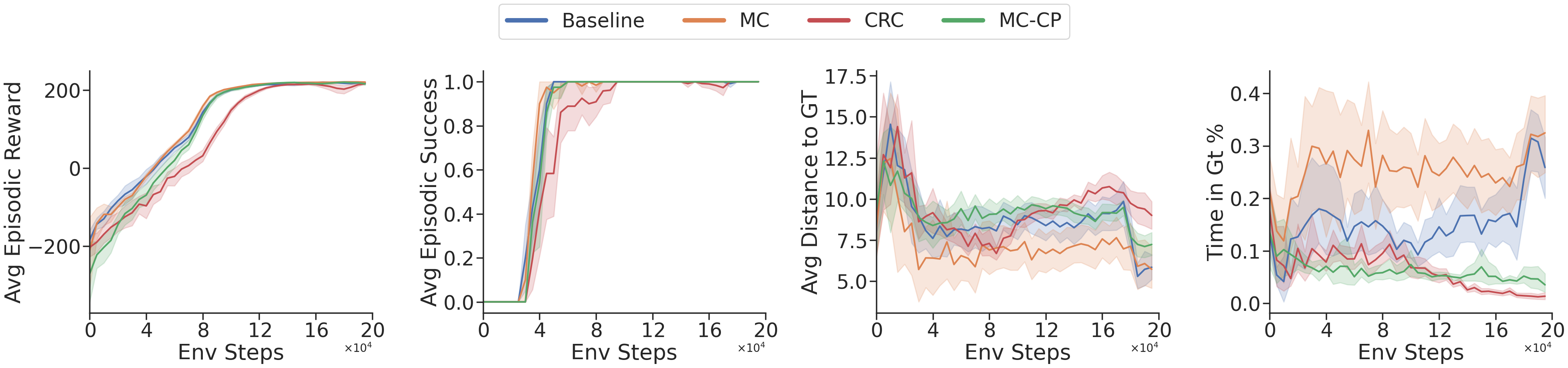
On the DeepMoon environment below, all four agents eventually learn the task well, reaching similarly high episodic reward and near-perfect success, so the more conservative conformal maps do not prevent effective navigation. The real difference appears in the safety metrics: CRC and MC-CP keep a consistently larger distance from ground-truth hazards and spend far less time inside hazardous regions than Baseline and MC. Importantly, MC does not deliver the same safety gains despite also using uncertainty estimates, which supports the main claim of COPPOL: the improvement comes from conformal calibration and its finite-sample coverage guarantees, not from generic uncertainty estimation alone.
The trajectory overlays below show the practical effect of COPPOL’s more conservative hazard maps. On the predicted hazard masks, both agents appear to avoid the crater regions successfully. However, when the same trajectories are overlaid on the ground truth, an important difference becomes clear: the baseline prediction has failed to capture some true craters, so the baseline agent is only apparently safe under its own imperfect map. In reality, it passes through hazardous regions that were missed by perception. By contrast, COPPOL’s more conservative conformalized mask captures more of these missed hazards, leading to a trajectory that is safer not just with respect to the prediction, but with respect to the true environment as well.

For the noisy results below, we inject corruption into the perception pipeline to mimic the kind of imperfect sensing an off-world robot may face in practice, such as sensor noise, transmission artefacts, occlusion, or even radiation-related degradation in orbital imagery.
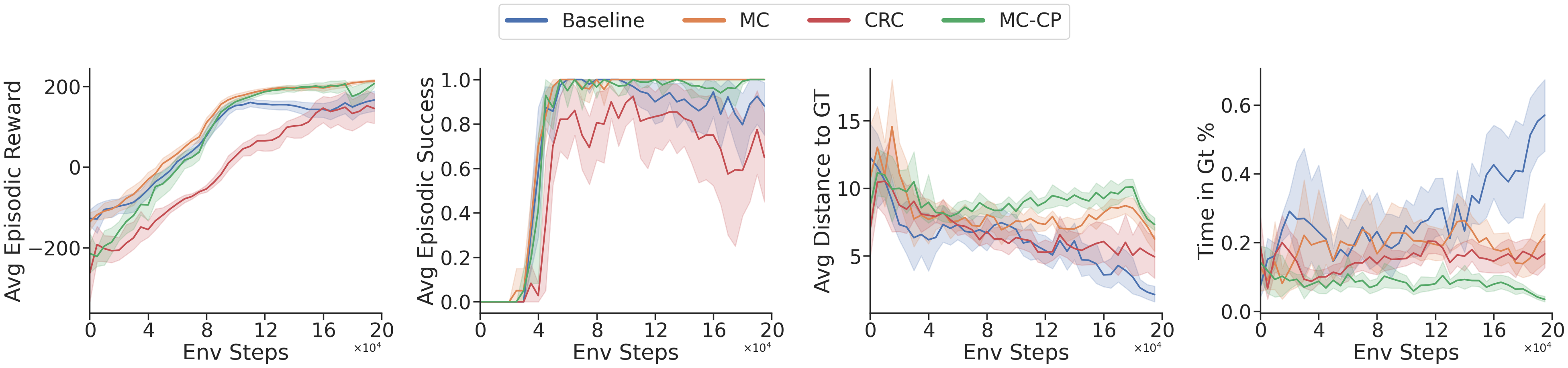
The key takeaway is that task performance alone does not tell the full story: even under noise, the baseline agent can still achieve reasonable reward and success, but its safety deteriorates badly, with the lowest distance to ground-truth hazards and by far the highest time spent in hazardous regions. By contrast, the conformal methods remain much more robust, especially MC-CP, which preserves high reward and success while maintaining the greatest clearance from hazards and the lowest hazard exposure. This is exactly the behaviour we want under imperfect perception: not just reaching the goal, but doing so safely when the hazard map itself has become unreliable.
Conclusion#
In this paper, we introduced COPPOL, a perception-to-policy framework for safer robot navigation under imperfect perception. By combining conformal prediction with hazard segmentation, COPPOL produces calibrated hazard maps with finite-sample guarantees on missed hazards, which are then used by an RL planner to generate safer trajectories. Across both standard and noisy settings, COPPOL improves hazard coverage, reduces time spent in dangerous regions, and maintains strong navigation performance, showing that safer planning depends not just on uncertainty estimates, but on principled calibration. Future work will explore richer perception models, more challenging off-world environments, and stronger integration between calibrated perception and downstream decision-making. I encourage you to read the full paper, published at SAC ’26.
References#
[1] NASA Jet Propulsion Laboratory (2024) Map a Mars Rover Driving Route. Available at: https://www.jpl.nasa.gov/edu/resources/project/map-a-mars-rover-driving-route/ (Accessed: 12 March 2026).
[2] Qutub, S., Geissler, F., Peng, Y., Gräfe, R., Paulitsch, M., Hinz, G. and Knoll, A., 2022, June. Hardware faults that matter: understanding and estimating the safety impact of hardware faults on object detection DNNs. In International Conference on Computer Safety, Reliability, and Security (pp. 298-318). Cham: Springer International Publishing.